機器翻譯作為人工智能領(lǐng)域的核心技術(shù)之一,近年來取得了令人矚目的進(jìn)展。本文將從基礎(chǔ)理論出發(fā),系統(tǒng)解讀機器翻譯的技術(shù)發(fā)展、核心算法、行業(yè)應(yīng)用及未來趨勢,為技術(shù)開發(fā)者提供全面的參考。
一、機器翻譯的技術(shù)演進(jìn)
機器翻譯的發(fā)展可分為三個階段:基于規(guī)則的機器翻譯(RBMT)、統(tǒng)計機器翻譯(SMT)和神經(jīng)機器翻譯(NMT)。早期RBMT依賴語言學(xué)家手工編寫的語法規(guī)則,雖然準(zhǔn)確但擴展性差;SMT引入概率統(tǒng)計模型,通過平行語料訓(xùn)練實現(xiàn)翻譯,顯著提升了翻譯質(zhì)量;而當(dāng)前主流的NMT采用端到端的神經(jīng)網(wǎng)絡(luò)架構(gòu),通過編碼器-解碼器結(jié)構(gòu)實現(xiàn)上下文感知的翻譯,在流暢度和準(zhǔn)確性上實現(xiàn)了質(zhì)的飛躍。
二、神經(jīng)機器翻譯的核心技術(shù)
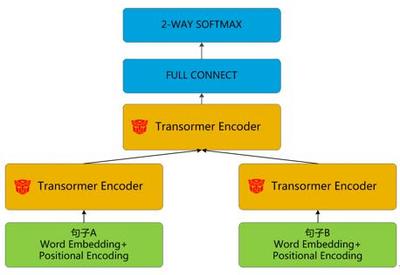
- 編碼器-解碼器架構(gòu):編碼器將源語言句子轉(zhuǎn)換為向量表示,解碼器基于該表示生成目標(biāo)語言句子。當(dāng)前主流模型如Transformer通過自注意力機制(Self-Attention)有效捕捉長距離依賴關(guān)系,顯著提升了翻譯質(zhì)量。
- 注意力機制:允許模型在生成每個目標(biāo)詞時動態(tài)關(guān)注源句子的相關(guān)部分,解決了傳統(tǒng)序列到序列模型的信息瓶頸問題。
- 預(yù)訓(xùn)練與微調(diào):基于大規(guī)模語料預(yù)訓(xùn)練模型(如BERT、GPT)再針對特定領(lǐng)域微調(diào),已成為提升專業(yè)領(lǐng)域翻譯效果的關(guān)鍵技術(shù)。
三、技術(shù)挑戰(zhàn)與解決方案
- 數(shù)據(jù)稀缺問題:針對低資源語言的翻譯,可采用遷移學(xué)習(xí)、數(shù)據(jù)增強和多語言聯(lián)合訓(xùn)練等方法。
- 領(lǐng)域適應(yīng)性:通過領(lǐng)域自適應(yīng)技術(shù)(如對抗訓(xùn)練、領(lǐng)域感知注意力)提升模型在醫(yī)療、法律等專業(yè)領(lǐng)域的表現(xiàn)。
- 實時性與效率:模型壓縮、知識蒸餾和硬件加速(如GPU/TPU優(yōu)化)助力在實際場景中的高效部署。
四、行業(yè)應(yīng)用與未來發(fā)展
機器翻譯已廣泛應(yīng)用于跨境電商、國際商務(wù)、內(nèi)容本地化、實時通信等場景。隨著多模態(tài)翻譯(文本-圖像-語音融合)、低資源語言突破及個性化翻譯技術(shù)的發(fā)展,機器翻譯正朝著更智能、更人性化的方向演進(jìn)。倫理問題如翻譯偏見、數(shù)據(jù)隱私等也需要技術(shù)社區(qū)共同關(guān)注和解決。
機器翻譯技術(shù)的快速發(fā)展離不開算法創(chuàng)新、算力提升和數(shù)據(jù)積累的協(xié)同驅(qū)動。作為開發(fā)者,深入理解技術(shù)原理并緊跟前沿動態(tài),將有助于在智能技術(shù)領(lǐng)域持續(xù)創(chuàng)造價值。